
Introduction
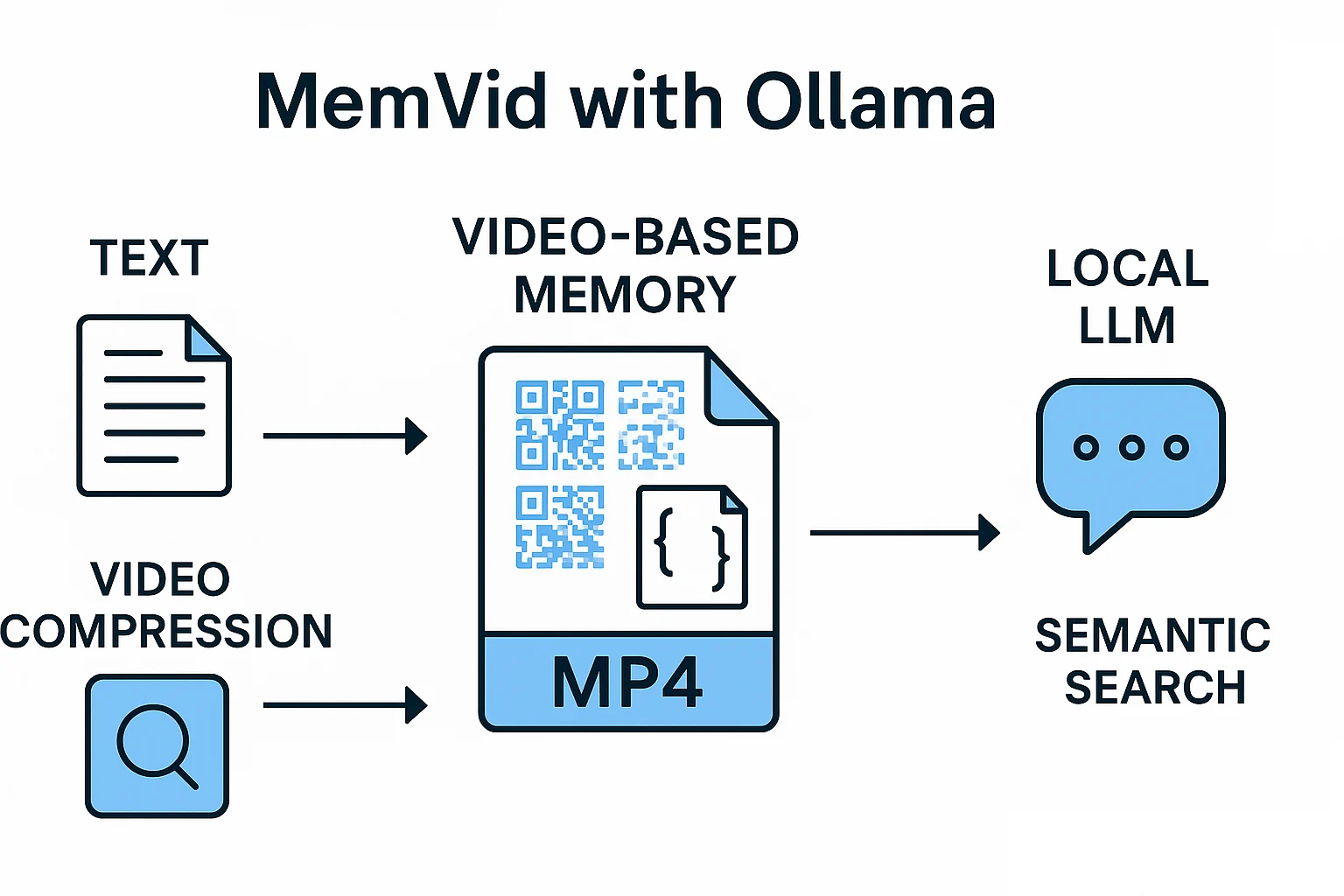
As AI applications become more complex, lightweight and scalable memory becomes essential. MemVid with Ollama introduces an elegant solution: turning text into a compressed video format that can be searched semantically, entirely offline. This method allows developers to bypass vector databases, rely on fast local retrieval, and use large language models like Qwen3 for contextual chat. In this blog, you’ll discover what makes MemVid with Ollama powerful and how you can implement it on your machine.
What is MemVid?
A Video-Based AI Memory Library
MemVid is a Python-based tool that encodes textual data into MP4 video files. The embeddings of the text chunks are written frame-by-frame into a compressed video, drastically reducing storage size while enabling efficient memory retrieval. This method ensures that memory systems are portable, scalable, and database-free.
How MemVid with Ollama Works? Turning Text into Video Memory
Step-by-Step Workflow of MemVid with Ollama
Here’s how MemVid with Ollama transforms plain text into compressed, searchable, and retrievable memory:
- Text → Chunk → Embed → QR Code Frame: Input is divided into chunks, embedded via
nomic-embed-text, and encoded as QR codes. - Frames → MP4 via OpenCV + ffmpeg: QR images are stitched into an MP4 using efficient codecs like H.264 or H.265.
- Index → FAISS + Metadata JSON: Embeddings are stored in FAISS along with a JSON file mapping embeddings to frames.
- Query → Embed → FAISS Cosine Match → Frame Seek → Decode QR → Return Text: Searches embed your question, find the nearest vectors, seek the right frame, decode, and return the original content.
Key Features and Advantages of MemVid with Ollama
MemVid with Ollama introduces a groundbreaking approach to memory storage and retrieval by turning video files into compact, intelligent databases. Designed for speed, efficiency, and offline accessibility, MemVid offers developers a powerful tool for building local-first AI applications. Below is a summary of its key features and advantages:
| Feature | Why It Matters |
|---|---|
| Video-as-Database | One MP4 file contains all your memory—portable, shareable, versionable. |
| Sub-second Semantic Search | Local SSD + FAISS = instant retrieval for retrieval-augmented generation (RAG). |
| Massive Storage Efficiency | 10× smaller footprint vs classic vectordbs—thanks to video compression. |
| Offline-First Architecture | Works with no internet connection; ideal for edge devices and secure environments. |
| PDF Ingestion Support | Load entire books or reports with a single call to add_pdf(). |
| Simple, Fast API | Just 3 lines to encode, 5 to chat—great for rapid prototyping. |
Why MemVid Stands Out
Portability, Speed, and Simplicity
MemVid avoids the need for cloud APIs or heavy databases. It can store millions of text entries in a single video file and supports sub-second search. Developers only need Python and a few dependencies, making it highly accessible. Integration with Ollama enables a seamless pipeline for embeddings and responses, all without an internet connection.
Integrating MemVid with Ollama
The Role of Ollama
Ollama serves as the local backend for both embedding generation and LLM-based responses. Once the models are pulled, you can use them fully offline. In our case, we use nomic-embed-text to build memory, and qwen3:latest to generate intelligent answers to user queries.
Step-by-Step Local Tutorial: MemVid with Ollama
This section walks you through creating your offline memory assistant using MemVid with Ollama. It includes checking Ollama’s status, generating memory, and chatting using local models.
1. Install Requirements
Start by installing the MemVid library and PDF support:
pip install memvid pyPDF2Download the embedding and LLM models:
ollama pull nomic-embed-text
ollama pull qwen3:latest2. Python Script to Create and Use Memory
Below is a full working example. Save this in a Python file like memvid_demo.py and run it locally.
import requests
import json
from memvid import MemvidEncoder, MemvidRetrieverdef check_ollama():
try:
response = requests.get("http://localhost:11434/api/tags", timeout=5)
if response.status_code == 200:
models = response.json().get("models", [])
print(f"✅ Ollama is running with {len(models)} models")
for model in models:
print(f" - {model['name']}")
return True
else:
print("❌ Ollama is not responding properly")
return False
except Exception as e:
print(f"❌ Cannot connect to Ollama: {e}")
print("Please start Ollama with: ollama serve")
return Falsedef ollama_chat(prompt, context=""):
url = "http://localhost:11434/api/generate"
if context:
full_prompt = f"Based on this context: {context}\n\nQuestion: {prompt}\nAnswer:"
else:
full_prompt = prompt
payload = {
"model": "qwen3:4b",
"prompt": full_prompt,
"stream": False
}
try:
response = requests.post(url, json=payload, timeout=60)
response.raise_for_status()
result = response.json()
return result.get("response", "No response received")
except Exception as e:
return f"Error with Ollama: {e}"def main():
print("🧠 Memvid + Ollama Simple Demo")
if not check_ollama():
returndocs = [
"Elephants are the largest land animals on Earth.",
"The Amazon River is one of the longest rivers in the world.",
"The moon affects ocean tides due to gravitational pull.",
"Honey never spoils and can last thousands of years.",
"Mount Everest is the highest mountain above sea level.",
"Bananas are berries, but strawberries are not.",
"The Sahara is the largest hot desert in the world.",
"Octopuses have three hearts and blue blood."
]
print("🧪 Creating memory from documents...")
encoder = MemvidEncoder()
encoder.add_chunks(docs)
encoder.build_video("demo_memory.mp4", "demo_index.json")
print("✅ Memory created!")
retriever = MemvidRetriever("demo_memory.mp4", "demo_index.json")
print("\n🔍 Testing search...")
query = "deserts and rivers"
results = retriever.search(query, top_k=3)
print(f"Search results for '{query}':")
for i, result in enumerate(results, 1):
print(f"{i}. {result}")
print("\n🧠 Testing with Ollama...")
context = "\n".join(results)
response = ollama_chat("Tell me something about natural wonders.", context)
print(f"Ollama response:\n{response}")
print("\n💬 Interactive mode (type 'quit' to exit):")
while True:
user_input = input("\nAsk anything: ").strip()
if user_input.lower() in ['quit', 'exit']:
break
if user_input:
search_results = retriever.search(user_input, top_k=3)
context = "\n".join(search_results)
response = ollama_chat(user_input, context)
print(f"\n🤖 {response}")if name == "main":
main()More details follow the official GitHub: https://github.com/Olow304/memvid
Conclusion
The combination of video-based memory and local language models is not just a creative hack—it’s a genuinely scalable solution for offline, fast, and intelligent memory systems. MemVid with Ollama lets you build assistants, libraries, and search tools with just Python and a video file. From compressing millions of knowledge chunks to chatting with context, this duo delivers on performance and simplicity. Whether you’re a developer, researcher, or enthusiast, MemVid with Ollama gives you full control of your AI memory stack—no cloud required.
🚀 Want to know more about my journey in AI, tech tutorials, and digital exploration? Learn more about me here 👤 and follow my latest insights on Medium 📝 for in-depth articles, and feel free to connect with me on LinkedIn 🔗.
Md Monsur Ali is a tech writer and researcher specializing in AI, LLMs, and automation. He shares tutorials, reviews, and real-world insights on cutting-edge technology to help developers and tech enthusiasts stay ahead.



